
如果只把 Micron HBM4 理解成一条新品新闻,就会错过这轮 AI 内存周期最关键的变化:存储的估值锚,正在从传统的 DRAM/NAND 价格波动,切向“谁能在 AI 产业链栏目 里率先把 HBM4 量产、先进封装和客户共设计协同起来”。Micron 在 2026 年 3 月 16 日宣布,面向 NVIDIA Vera Rubin 的 HBM4 36GB 12H 已进入高量产,带宽超过 2.8 TB/s、能效较 HBM3E 提升超过 20%[1][2]。
这也是为什么 `Micron HBM4` 的 SERP 已经明显不是“财报快讯”意图,而是问答型 / 解释型意图:用户想知道 Micron 到底有没有 HBM4、量产到哪一步、是不是已经被客户锁单、以及这件事对整个 HBM4 与先进封装链意味着什么。与其再复述一遍新闻,不如把它放回 半导体周期 2026 主框架、BESI 混合键合信号 和 Rubin / HBM4 / NVLink 新分工 的同一条链里看。
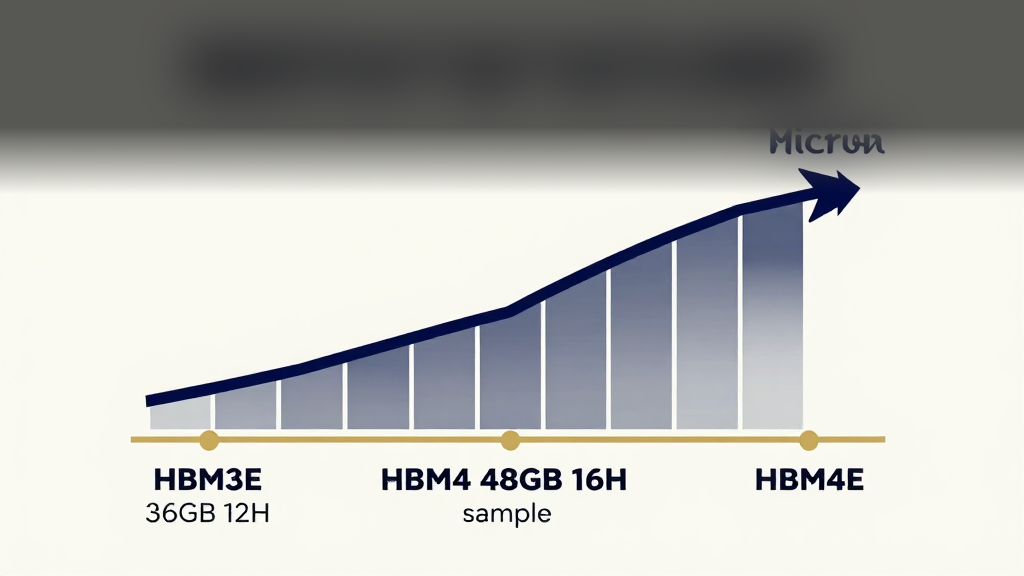
Micron HBM4 到底是什么,为什么现在是关键节点
Micron 官方把 HBM4 定义为“下一代 AI 平台的核心内存层”。相比 HBM3E,HBM4 的接口从上一代架构进一步升级到 2048-pin,总 pin speed 超过 11.0 Gbps,单 stack 带宽超过 2.8 TB/s,官方口径是带宽达到 HBM3E 的 2.3 倍、功耗效率改善超过 20%[1][2]。这不是简单的参数堆砌,因为 Rubin 这一代平台本身就是围绕 HBM4 与 NVLink 6 做协同设计的。NVIDIA 官方页面明确写到,Rubin GPU 采用 HBM4,而 NVLink 6 单 GPU 的 scale-up 带宽达到 3.6 TB/s[5]。
换句话说,Micron HBM4 之所以重要,不是因为“MU 也有 HBM 产品”,而是它直接嵌进了下一代 AI 机柜的系统约束。站内如果只看 NVIDIA FY2026 系统级深度,会看到 GPU 和整柜算力继续抬高;但把视角切到内存,会发现系统瓶颈已经从“有没有更多 GPU”转为“HBM4、base die、封装和验证能否跟上”。
| 维度 | HBM3E | HBM4 36GB 12H | HBM4 48GB 16H sample |
|---|---|---|---|
| 接口 | 上一代 HBM 接口 | 2048-pin | 2048-pin |
| pin speed | 上一代口径 | >11.0 Gbps | >11.0 Gbps 体系延伸 |
| 单 stack 带宽 | 基准 | >2.8 TB/s | 同架构下更高容量 |
| 容量 | 上一代主流 | 36GB | 48GB |
| 量产状态 | 已量产 | 2026Q1 已高量产 | 已向客户送样 |
| 下一节点 | — | 成熟良率爬坡 | 为 HBM4E / 更高密度铺路 |
真正的瓶颈不在“有没有 HBM4”,而在四个环节
如果只看第一层 headline,Micron 的 press release 像是在回答“Does MU have HBM4?”。但对投资者更有价值的问题其实是:为什么 HBM4 会比上一轮 HBM3E 更容易形成长周期供给约束?答案不在单颗 DRAM die,而在下面四个环节。
1. 1γ DRAM 制程决定了良率爬坡速度
Micron 在 2026 财年 Q2 prepared remarks 中明确说,1γ DRAM 节点已经是公司历史上爬坡最快、最早接近成熟良率的节点,并预计在 2026 年中成为 DRAM bit mix 的多数[4]。这意味着 HBM4 不只是“新封装”,它底层依赖的是更先进的 DRAM 节点。如果 1γ 没有稳定量产,HBM4 的高带宽、低功耗和更高容量就很难同步兑现。
2. 12H 到 16H 不只是加层,而是把 base die 和堆叠难度一起拉高
Micron 一边在量产 36GB 12H,一边已经向客户送样 48GB 16H。官方口径是 16H 带来较 12H 多 33% 的容量提升[1][4]。但层数往上走,不代表成本线性上升,而是对 base die、热管理、信号完整性和封装良率的要求同步抬高。市场未来盯的不是“16H 有没有”,而是 16H 能不能在客户验证窗口内变成稳定供货,而不是只停留在送样阶段。
3. 先进封装决定 HBM4 能不能变成系统产品
HBM4 不是孤立工作,它必须贴着 GPU / CPU / interposer 一起被封装成系统。也正因为如此,Lam Research 先进节点设备深度 和 BESI 混合键合文章 才会成为 Micron HBM4 的上游变量。Lam 官方把 HBM 描述为 3D stacking 和 cutting-edge packaging 的代表性方向,强调它是 AI 性能与能效的关键载体[6]。如果上游先进封装产能、cleanroom 空间和验证节奏卡住,HBM4 的实际出货弹性就不会完全体现为 Micron 自己的财报数字。
4. 客户共设计让“量产”不等于“自由出货”
NVIDIA Rubin 平台是当前最清晰的需求锚。Micron 的 press release 和 prepared remarks 都把 HBM4 与 Rubin 直接绑定,这说明 HBM4 已经进入了 joint engineering 的体系,而不是传统意义上“标准件做出来,等客户来买”[1][4][5]。这种共设计模式一方面提高了可见性,另一方面也让客户切换、验证和认证流程变得更长,所以市场才会开始追问它是否已被战略客户提前锁定。
为什么 MU 的估值锚,正在从“存储周期股”切向“AI 基础设施资产”
Micron 2026 财年 Q2 的财务数字已经说明,AI 需求对公司盈利结构的改写不是概念层面的。公司当季营收 238.6 亿美元,GAAP 每股收益 12.07 美元,净 capex 50 亿美元,调整后自由现金流 69 亿美元,期末现金、可交易投资和受限现金合计 167 亿美元[3][7]。Prepared remarks 里更直接指出,DRAM、NAND、HBM 以及各业务单元收入都创新高,而 Q3 收入指引 335 亿美元甚至超过 Micron 2024 财年的全年收入[4]。
| Micron FYQ2 2026 关键指标 | 数值 | 含义 |
|---|---|---|
| 营收 | 238.6 亿美元 | 同比高增,创公司纪录 |
| GAAP EPS | 12.07 美元 | 盈利能力显著抬升 |
| 净 capex | 50 亿美元 | 继续为供给紧平衡扩产 |
| 调整后自由现金流 | 69 亿美元 | AI 周期已经开始兑现现金流 |
| CDBU 收入 | 57 亿美元 | 数据中心已成 24% 收入来源 |
| 行业供需判断 | 紧平衡延续至 2026 年后 | 说明可见度并未止于一季财报 |
更重要的是,公司已经从传统 LTA 走向更强绑定的 strategic customer agreements。管理层在 3 月 18 日的 prepared remarks 中披露,Micron 已签下第一份五年期 SCA,并强调 DRAM / NAND 供需紧张可能延续到 2026 年之后[4]。这几乎就是对“Is Micron HBM4 sold out?”最接近官方的回答:Micron 没有逐季披露每一代 HBM 的满产状态,但它已经在用更长约束周期的客户协议和更长的供需紧平衡指引,告诉市场高价值 AI 内存不再是短单逻辑。
接下来真正要盯的四个变量
第一,看 HBM4 从 12H 到 16H 的良率兑现。 如果 48GB 16H 能顺利从送样过渡到认证并放量,Micron 的 ASP 和容量叙事会继续向上走;反之,市场会把 16H 当作“路线图上的承诺”。
第二,看 HBM4E 是否按 2027 年爬坡。 Micron 已明确表示 HBM4E 在开发中,并计划 2027 年进入 volume ramp[4]。这决定了这轮 AI 内存周期会不会变成一条 2026-2027 连续抬升的长坡,而不只是 HBM4 一代的短爆发。
第三,看先进封装链是否成为新的硬约束。 如果上游 cleanroom、封装和混合键合进展跟不上,Micron 的 HBM4 产能扩张不会完全转化为出货。也因此,站内读 Micron,不能脱离 BESI、Lam 和 半导体周期主线 分开看。
第四,看客户结构是否从“爆发式需求”走向“多年可见度”。 Micron 已经给出第一份五年期 SCA,这在历史上比普通存储周期更接近基础设施合同逻辑。若后续再出现更多类似协议,MU 的估值锚会继续从 commodity memory 向 AI infrastructure re-rating 靠拢。
结论:Micron HBM4 不是“有没有”,而是“能否持续把系统瓶颈变成盈利护城河”
所以这篇文章的核心结论并不复杂:Micron HBM4 已经不是概念验证阶段,官方口径是 2026 年一季度已高量产,并面向 NVIDIA Vera Rubin[1]。真正的问题也不再是 “MU 有没有 HBM4”,而是公司能不能把 1γ DRAM、12H/16H 堆叠、先进封装协同和客户共设计,持续转化成 2026-2027 的供需紧平衡与高毛利现金流。
如果这个问题的答案偏正面,那么 MU 的上行逻辑就不会只来自 DRAM spot price,而更像 NVIDIA 系统叙事 在内存侧的镜像:谁能提供系统级关键部件,谁就获得更长的订单可见度、更强的议价权和更稳定的估值中枢。
FAQ
Micron HBM4 是什么?
它是 Micron 面向下一代 AI 平台的高带宽内存产品,采用 2048-pin 接口、超过 11.0 Gbps 的 pin speed,单 stack 带宽超过 2.8 TB/s,定位就是服务像 NVIDIA Vera Rubin 这样的新平台[1][2][5]。
Micron 现在真的已经有 HBM4 了吗?
有。Micron 2026 年 3 月 16 日官方新闻稿明确写到,公司在 2026 年一季度已经开始高量产出货 HBM4 36GB 12H,并为 NVIDIA Vera Rubin 设计;同时还向客户送样了 48GB 16H[1][4]。
市场为什么会问 Micron HBM4 是否已经 “sold out”?
因为管理层同时披露了第一份五年期 strategic customer agreement,并反复强调 DRAM 和 NAND 的紧平衡可能持续到 2026 年之后[4]。官方没有逐季给出“全部售罄”的字样,但这些信号已经说明高价值 AI 内存的可见度在拉长。
HBM 为什么比 DDR 更重要?
HBM 的目标不是替代普通服务器内存,而是把超高带宽、低延迟和更优能效贴近 GPU / AI 加速器本体。AI 训练、长上下文和高吞吐推理对内存带宽极度敏感,这正是 HBM4 价值密度高于传统 DDR 的原因[2][5][6]。
方法论与数据来源
这篇文章按“系统平台需求锚 → Micron 产品节点 → 先进封装约束 → 财务兑现 → 后续观测变量”的顺序展开,而不是按传统财报点评方式平铺。数据主要来自:Micron 2026 年 3 月 16 日 HBM4 高量产新闻稿、Micron HBM4 官方产品页、Micron FYQ2 2026 财报新闻稿、Micron FYQ2 2026 prepared remarks、NVIDIA Vera Rubin 官方页面、Lam Research 官方 advanced memory 资料,以及 Micron 向 SEC 提交的 Q2 10-Q。所有关键判断尽量落在官方已披露事实之上,推断部分在文中以“意味着/代表/决定了”明确标识。
数据来源:[1] Micron, March 16, 2026 press release. [2] Micron HBM4 product page. [3] Micron fiscal Q2 2026 earnings release. [4] Micron fiscal Q2 2026 prepared remarks. [5] NVIDIA Vera Rubin NVL72 official page. [6] Lam Research advanced memory solutions / packaging materials. [7] Micron FYQ2 2026 SEC filing.
免责声明:本文基于公开资料做研究性整理,不构成任何投资建议、买卖推荐或目标价判断。
常见问题
这篇文章属于 m8 的哪个研究入口?
这篇文章归入 AI产业链 主线,建议先从 AI产业链栏目 进入,再结合研究目录里的相邻专题一起看。
读完这篇后,下一步应该看什么?
优先继续看 AI产业链文章列表、HBM / 先进封装、AI产业链研究中心。这些入口能把单篇内容放回市场、行业和方法论框架里。
后续最需要跟踪哪些变量?
后续重点跟踪:AI capex、GPU/HBM/先进封装供给、服务器交付、软件变现和产业链利润分配是否兑现。
这篇内容可以直接当作投资建议吗?
不可以。m8 的文章用于整理公开信息、研究框架和风险变量,不构成个股买卖建议,也不替代个人的仓位管理和风险评估。
m8 会如何更新这类主题?
如果后续出现财报、政策、订单、资金流或估值假设的关键变化,m8 会在对应栏目和专题页继续补充更新,并通过内链把新旧文章串起来。
同一主题继续读
这篇文章属于 m8 的「semiconductor-equipment-and-hbm」研究链。继续阅读下面几篇,可以把公司、产业链和宏观变量放到同一张图里理解。